01 기본 아키텍처
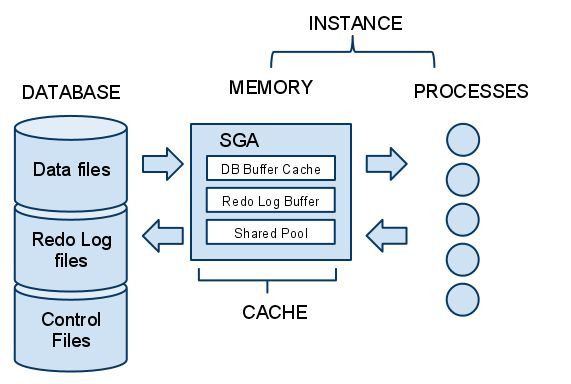
오라클은 데이터베이스와 이를 액세스하는 프로세스 사이에 SGA라는 메모리 캐시 영역을 둠
워드와의 차이점
|
워드
|
오라클 디비
|
|
디스크 경유
|
메모리 캐시 경유(매우 빠름)
|
|
사용자만 접근
|
많은 프로세스가 접근(데이터 보호 Lock)
|
|
파일단위
|
블록단위
|
|
캐시와 파일 간의 주기적 동기화로 자동저장
|
백그라운드에서 DBWR와 CKPT 프로세스로 캐시와 데이터파일 간 동기화 주기적 수행
|
DBMS 정의
DBMS 마다 데이터베이스 정의가 조금씩 다르다.
오라클은 디스크에 저장된 데이터집합을 데이터베이스라고 부른다.
SGA 를 액세스하는 프로세스 집합을 인스턴스
오라클 인스턴스

오라클 인스턴스는 아래의 두 가지로 나뉨
|
서버 프로세스
|
백그라운드 프로세스
|
|
사용자가 던지는 명령 처리
|
기본적으로 수반되는 작업, 서버 프로세스가 완료하지 못한 작업을 수행
|
오라클 접속 과정
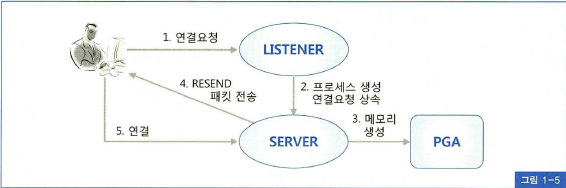
- 하나의 프로세스 PGA(서버 프로세스만을 위한 독립적인 메모리 공간) 메모리 할당
- SQL 문 수행을 위해 매번 요청하면 비용 큼
- 위 원인으로 Connection Pool 필요. 한번 커넥션 맺으면 Pooling 하고 있다가 반복 재사용
RAC

- RAC(Real Application Cluster) 환경에서는 하나의 데이터베이스를 액세스하는 다중 인스턴스로 구성
- 공유 캐시(Shared Cache) 방식 지원하여 로컬 캐시(Local Cache)에 없는 데이터 블록을 이웃 노드에서 전송받아 서비스하는 글로벌 캐시(Global Cache) 개념 사용
- 커밋하지 않은 블록에 디스크를 경유하지 않고 Dirty Buffer(메모리와 디스크 간 동기화되지 않은 버퍼) 갱신 수행
디스크를 거치는 과정은 핑(Ping) 이라 불렀다.
SQL 트레이스
SQL 튜닝 시 가장 많이 사용하는 툴킷 (TKProf)
SQL 트레이스로 Call 통계표를 확인할 수 있다.
여섯 번째 컬럼 query 는 Parse, Execute, Fetch Call의 버퍼 수이며
일곱 번째 컬럼 current 는 Insert, Update, Delete와 같은 current mode에서의 버퍼 수이다.
위 두 컬럼의 차이점을 인지하고 있자.
02 DB 버퍼 캐시
사용자가 입력한 데이터를 데이터 파일에 저장하고 이를 다시 읽는 과정에서 거쳐가는 캐시 영역인 SGA 구성 요소 중 하나
(1) 블록 단위 I/O
- 오라클에서 I/O 는 블록 단위
- 메모리 버퍼와 데이터파일 간 읽기, 쓰기 모두 블록 단위
- single block read : 인덱스 경유 시 한 번에 한 블록씩 읽음
- multiblock read : Full Scan 시 성능 향상을 위해 한 번에 여러 개 블록 읽음
- DBWR 프로세스 : 버퍼 캐시로부터 변경된 블록 주기적으로 데이터파일에 기록하는 작업 수행(성능 향상을 위해 한 번에 여러 블록 처리)
SQL 성능을 좌우하는 가장 중요한 성능지표는 액세스 하는 블록 개수이며 옵티마이저 판단에도 큰 영향 미침
(2) 버퍼 캐시 구조

DB 버퍼 캐시는 해시 테이블 구조로 관리
|
용어
|
설명
|
|
데이터 블록 주소(DBA, Data Block Address)
|
데이터 블록을 해싱하기 위해 사용되는 키 값
|
|
해시 버킷(Hash Bucket)
|
레코드의 키값, 같은 페이지의 개념
|
|
해시 체인(Hash Chain)
|
각 DBA의 해시값은 같은 해시 버킷에 연결 리스트 구조로 연결되며 각각의 연결 리스트를 해시 체인이라고 함
|
|
버퍼 헤더(Buffer Header)
|
해시 체인이 연결되는 부분. 실제 버퍼에 대한 포인터 값을 지님
|
찾고자 하는 DBA를 해시값으로 변환해서 해당 해시 버킷에서 체인을 따라 스캔하다가 찾아지면 바로 읽고,
찾지 못하면 디스크에서 읽어 해시 체인에 연결한 후 읽는다.
버킷에 기록되는 엔트리 개수를 일정 수준 유지할 수만 있다면 검색 속도가 가장 빠르다.
(3) 캐시 버퍼 체인
|
용어
|
설명
|
|
래치(Latch)
|
캐시는 공유 메모리 영역(SGA)에 존재하여 같은 리소스에 대한 동시 액세스에 직렬화가 필요
이를 위해 구현된 일종의 Lock 메커니즘을 래치라 한다.
각 해시 체인은 래치에 의해 보호된다.
데이터 자체가 아닌 SGA에 공유된 자료 구조를 보호하는 개념
|
|
cache buffers chains 래치
|
새로운 버퍼 블럭에 대한 연결 및 해제 작업에 동시 진행을 방지하기 위한 래치
버퍼 캐시에 연결된 여러 체인구조를 보호
|
래치의 수는 매우 많으며 하나의 체인에 하나의 버퍼만 달리는 것을 목표로 해야 스캔하는 비용을 최소화할 수 있다.
(4) 캐시 버퍼 LRU 체인

버퍼 헤더는 해시 체인 뿐 아니라 LRU 체인에 의해서도 연결돼 있다.
버퍼 캐시가 사용 빈도 높은 테이블 블록 위주로 구성되도록 LRU 알고리즘을 사용해 관리된다.
- Dirty 리스트 : 캐시 내에서 변경됐지만, 아직 디스크에 기록되지 않은 Dirty 버퍼 블록들을 관리하며 LRUW(LRU Wirte) 리스트라고도 한다.
- LRU 리스트 : 아직 Dirty 리스트로 옮겨지지 않은 나머지 버퍼 블록들을 관리
- cache buffers lru chain : LRU 리스트를 보호하기 위해 사용하는 래치
모든 캐시 버퍼는 아래 세 가지 중 하나의 상태에 놓이게 된다.
|
버퍼 종류
|
설명
|
|
Free 버퍼
|
인스턴스 가동 후 데이터가 읽히지 않아 비어 있는 상태(Clean 버퍼) 거나, 데이터가 담겼지만 언제든지 덮어 써도 무방한 블록
새 데이터 블록 로딩 시 먼저 Free 버퍼를 확보 해야함
|
|
Dirty 버퍼
|
버퍼에 캐시 이후 변경 발생했지만, 디스크에는 기록되지 않아 데이터 파일 블록과 동기화 필요한 블록
버퍼 블록 재사용을 위해선 디스크에 먼저 기록되어야 하며, 기록되는 순간 Free 버퍼로 바뀜
|
|
Pinned 버퍼
|
읽기/쓰기 작업을 위해 현재 액세스되고 있는 버퍼 블록
|
03 버퍼 Lock
(1) 버퍼 Lock 이란
두 개 이상의 프로세스가 동시에 버퍼 내용을 읽는 것을 방지하기 위해 버퍼 헤더로부터 버퍼 Lock 을 획득해야 한다. 획득 했다면 래치를 곧바로 해제해야 한다.
- Share 모드 : 버퍼 내용을 읽을 때만 사용
- Exclusive 모드 : 한 시점에서 한 프로세스만 얻을 수 있는 모드로 버퍼 내용을 변경할 때 사용
- buffer busy waits : 버퍼 Lock 대기자 목록에 등록돼 있는 동안 발생하는 이벤트
(2) 버퍼 핸들
버퍼 Lock을 설정하는 것은 자신이 현재 그 버퍼를 사용 중임을 표시 해두는 것으로 버퍼 Pin 이라 표현한다.
- 버퍼 핸들(Buffer Handle) : 버퍼 헤더에 Pin을 설정하려고 사용하는 오브젝트
- cache buffer handles 래치 : 버퍼 핸들을 얻기 위한 래치
(3) 버퍼 Lock 의 필요성
데이터 변경 시 DML Lock 를 통해 보호하도록 또 다른 Lock 을 획득
∵ 오라클은 레코드 갱신 시 블록 단위로 I/O 수행
두 프로세스가 로우 단위 Lock 을 시도 시 Lost Update 문제가 생겨 블록 자체의 정합성(Intergrity)이 깨지게 된다.
∴ 블록 자체로의 진입을 직렬화
Pin 된 버퍼 블록은 버퍼 캐시 전체를 비우려해도 밀려나지 않는다.
alter system flush buffer_cache;
비공식적이지만 9i 에서는 아래 명령으로 버퍼 캐시를 비울 수 있다.
alter system set events 'immediate trace name flush_cache';
(4) 버퍼 Pinning
- 버퍼를 읽고 버퍼 Pin을 즉각 해제하지 않고 데이터베이스 Call이 진행하는 동안 유지하는 기능이다.
- 같은 블록을 반복적으로 읽을 때 버퍼 Pinning 으로 래치 획득 과정을 생략한다면 논리적인 블록 읽기 횟수를 줄일 수 있다.
- 같은 블록을 재방문할 가능성 있는 큰 몇몇 오퍼레이션 수행 시 사용
- 한 데이터베이스 내에서만 유효. 즉, Call 끝나면 Pin 해제
- 전통적인 버퍼 Pinning 이 적용된 지점은 인덱스 리프 블록
- Index Range Scan 시 인덱스와 테이블 블록 교차 방문할 때 테이블 블록의 I/O 만 증가하는 이유가 여기있음
- 인덱스로 경유 시 인덱스 클러스터링 팩터(rowid 정렬 순서가 인덱스 키 값 정렬 순서와 거의 일치)가 좋다면 같은 테이블 블록 반복 액세스할 가능성 커짐
04 Redo
데이터파일과 컨트롤 파일에 가해지는 모든 변경사항을 하나의 Redo 로그 엔트리로서 Redo 로그에 기록
Redo 로그는 Online Redo 와 Archived(Offline) Redo 로그로 구성된다.
|
로그
|
설명
|
|
Online Redo
|
Redo 로그 버퍼에 버퍼링된 로그 엔트리를 기록하는 파일
최소 두 개 이상의 파일로 구성
현재 사용 중인 Redo 로그 파일 꽉 차면 다음 파일로 로그 스위칭(log switching) 발생하며 모든 파일이 꽉 차면 다시 첫 번째부터 재사용하는 라운드 로빈 방식 사용
|
|
Archived Redo
|
Online Redo 로그가 재사용되기 전에 다른 위치로 백업해둔 파일
|
Redo 로그는 아래 3가지 목적을 위해 사용된다.
|
사용 목적
|
설명
|
|
Database Recovery
|
물리적인 Media Fail 발생 시 복구를 위해 사용
이때 Archived Redo 로그를 이용
|
|
Cache Recovery
|
캐시의 변경사항이 디스크에 기록되지 않은 상태에서 정전 발생해 비정상 종료로 트랜잭션 데이터 유실에 대비
roll forward 단계 → Instance Crash 후 시스템 재기동하면 Online Redo 로그에 저장된 기록을 읽어 마지막 체크 포인트 이후 사고 전까지의 수행된 트랜잭션 재현
roll back 단계 → Cache Recovery 완료 후 Undo 데이터로 셧다운 시점에 커밋안된 트랜잭션을 모두 롤백. 즉, Transaction Recovery 진행
모두 완료 후 커밋 성공한 데이터만 남아 데이터베이스는 완전 동기화 상태됨
|
|
Fast Commit
|
변경사항을 Append 방식으로 기록하고 DBWER 로 동기화하여 나중에 배치 방식으로 일괄 수행
메모리상의 버퍼 블록에만 기록되고 디스크에 기록되지 않았지만 Redo 로그를 믿고 빠르게 커밋
오라클은 별도의 Lock 매니저 없이 로우 Lock을 구현한 Delayed 블록 클린 아웃 매커니즘
∴ 커밋 시점엔 Undo 세그먼트 헤더의 트랜잭션 테이블만 커밋 기록, 블록 클린 아웃은 나중에 수행
|
Redo 레코드 기록 시 바로 Redo 로그 파일에 저장하지 않고 Redo 로그 버퍼에 먼저 기록한다. 그리고 일정 시점마다 LGWR 프로세스에 의해 Redo 로그 버퍼의 내용을 Redo 로그 파일에 기록한다.
이 시점은 다음과 같다.
|
시점
|
설명
|
|
3초마다 DBWR 프로세스로 부터 신호 받을 때
|
대량의 트랜잭션 일괄 반영
|
|
로그 버퍼에 1/3 차거나 기록된 Redo 레코드량 1MB 넘을 때
|
대량의 트랜잭션 일괄 반영
|
|
사용자가 커밋 또는 롤백
|
Fast Commit 의 핵심. 최소한 메모리가 아닌 디스크 상에 안전히 저장됐음을 확인해야 함(Log Force at Commit)
|
정리하면, 버퍼 캐시의 블록 버퍼를 갱신 전에 Redo 엔트리를 로그 버퍼에 기록하고 DBWR가 버퍼 캐시로부터 Dirty 블록들을 디스크에 기록 전에 LGWR가 해당 Redo 엔트리를 모두 Redo 로그 파일에 기록했음을 보장해야 한다.
이를 Write Ahead Logging이라 한다.
Fast Commit 매커니즘을 정리해보자.
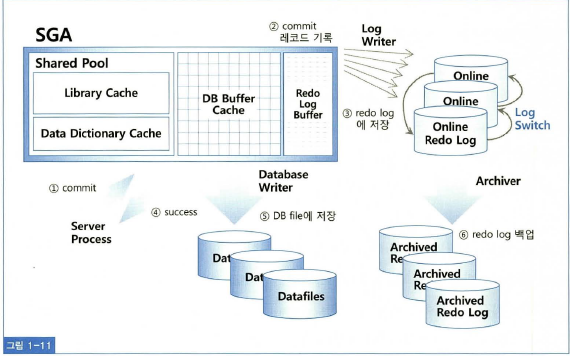
사용자가 커밋 또는 롤백 시마다 log file sync 라는 대기 이벤트가 발생하는데, 이는 LGWR 프로세스가 로그 버퍼 내용을 Redo 로그 파일에 기록할 때까지 서버 프로세스가 대기하는 현상때문에 발생한다.
05 Undo
- AUM 도입
- 익스텐트(Extent) 단위
- Undo 블록들 버퍼 캐시에 캐싱하고 데이터 유실 방지로 변경사항 Redo 로그에 로깅
- 각 트랜잭션 별로 Undo 세그먼트 할당하고 해당 트랜잭션이 발생시킨 테이블과 인덱스의 변경사항들을 Undo 레코드 단위로 Undo 세그먼트 블록에 차곡차곡 기록
AUM
- Undo 세크먼트마다 하나의 트랜잭션이 할당되는 것을 목표로 세그먼트 개수를 오라클이 자동 관리
Undo 세그먼트에 저장된 정보는 아래 3가지 목적을 위해 사용
|
사용 목적
|
설명
|
|
Transaction Rollback
|
트랜잭션에 의한 변경사항을 최종 커밋하지 않고 롤백할 때 Undo 데이터를 이용
|
|
Transaction Recovery
|
Redo를 이용한 roll forward 단계 후 최종 커밋되지 않은 변경사항 모두 복구된다. 이때 Undo 세그먼트에 저장된 Undo 데이터를 사용
|
|
Read Consistency
|
Undo 데이터는 읽기 일관성(Read Consistency)을 위해 사용
|
(1) Undo 세그먼트 트랜잭션 테이블 슬롯
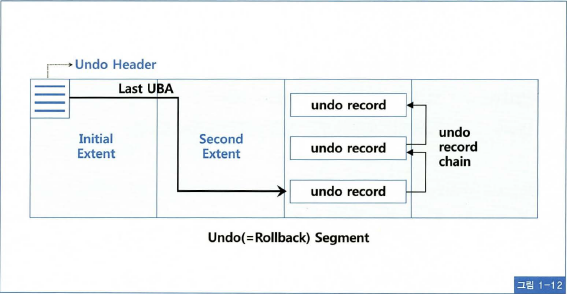
Undo 세그먼트 헤더엔 트랜잭션 테이블 슬롯(Transaction Table slot)이 위치하는데, 각 슬롯에 기록되는 사항은 다음과 같다.
- 트랜잭션 ID
- 트랜잭션 상태정보(Transaction Status)
- 커밋 SCN
- Last UBA(Undo Block Address)
- 마지막 Undo 레코드 뒤에 추가해 나가는 일종의 포인터
- 체인 형태로 되어 있어 거슬러 올라가며 작업 수행
- 쓰기 완료 시 새로운 Undo 블록을 할당받아 계속 씀
- 기타
슬롯을 할당받아야 트랜잭션을 시작하며 슬롯에 자신이 현재 Active 상태임을 표시하고 갱신들 시작한다.
트랜잭션 슬롯을 곧바로 얻지 못해 기다릴 때 undo segment tx slot 대기 이벤트가 발생한다.
Undo 블록에 Undo 레코드가 차례로 기록되며 각 DML 오퍼레이션 별로 Undo 레코드에 기록되는 내용은 다음과 같다.
|
DML
|
내용
|
|
Insert
|
추가된 레코드의 rowid
|
|
Update
|
변경되는 컬럼에 대한 before image
|
|
Delete
|
지워지는 로우의 모든 컬럼에 대한 before image
|
v$transaction 뷰의 used_ublk 와 used_urec 컬럼을 통해 현재 사용 중인 Undo 블록 개수와 현재까지 기록한 Undo 레코드 양을 확인할 수 있다.

커밋되지 않은 트랜잭션은 다른 트랜잭션에 의해 재사용되지 않는다.
커밋하면 트랜잭션 정보가 Active 에서 commiteted 로 변경되고 이 시점의 커밋 SCN 을 트랜잭션 슬롯에 저장하고 다른 트랜잭션에 의해 재사용될 수 있다.
Undo Retention
- 트랜잭션 완료돼도 지정된 시간 동안은 가급적 Undo 데이터를 재사용하지 말라고 힌트를 주는 것
(2) 블록 헤더 ITL 슬롯

각 테이블 블록과 인덱스 블록 헤더에는 ITL(Interested Transaction List) 슬롯이 있다.
ITL 슬롯에 기록되는 내용은 다음과 같다.
- ITL 슬롯 번호
- 트랜잭션 ID
- UBA(Undo Block Address)
- 커밋 Flag
- Locking 정보
- 커밋 SCN

특정 블록의 레코드 갱신하기 위해 블록 헤더로부터 ITL 슬롯을 확보 받아야 한다.
거기에 트랜잭션 ID 를 기록하고 Active 상태를 표시 후 갱신이 가능하다.
오라클은 ITL 슬롯 부족으로 블로킹 현상을 최소화할 수 있도록 테이블과 인덱스 생성 시 다음 파라미터를 지정할 수 있다.
|
옵션
|
설명
|
|
initrans
|
처음 포맷 시 블록 헤더에 ITL 슬롯을 할당할 개수
|
|
maxtrans
|
지정된 개수만큼 할당 가능
|
|
pctfree
|
예약할 수 있는 공간
|
(3) Lock Byte
레코드가 저장되는 로우마다 그 헤더에 Lock Byte 를 할당해 로우를 갱신 중인 트랜잭션의 ITL 슬롯 번호를 기록해 둔다.
이것이 로우 단위 Lock이며, 트랜잭션 Lock을 조합하여 로우 Lock 을 구현
06 문장수준 읽기 일관성
(1) 문장수준 읽기 일관성이란
단일 SQL문이 수행되는 도중 다른 트랜잭의 추가, 변경, 삭제가 발생해도 일관성 있는 결과 집합을 리턴하는 것이다.
|
계좌번호
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
잔고
|
1,000
|
1,000
|
1,000
|
1,000
|
1,000
|
1,000
|
1,000
|
1,000
|
1,000
|
1,000
|
< 사례 1 >
TX1 : select sum(잔고) from 계좌
위 쿼리 진행동안 TX2 에서 아래 Insert 문을 통해 새 계좌의 잔고 데이터를 추가하고 커밋했다.
TX2> insert into 계좌(계좌번호, 잔고) values(11, 1000); TX2> commit;
맨 뒤쪽에 추가되면 포함되겠지만 이미 읽고 지나간 위치에 삽입되면 총계에서 누락된다.
< 사례 2 >
사례 1번과 동일하게 TX1이 총합을 구하는 쿼리가 수행 중이다.
계좌 이체를 처리하는 아래 트랜잭션 TX2가 동시에 진행 중이라 가정하자.
TX2> update 계좌 set 잔고 = 잔고 + 100 where 계좌번호 = 7 --1 TX2> update 계좌 set 잔고 = 잔고 - 100 where 계좌번호 = 7 --2 TX2> commit;
- TX1: 2번 계좌까지 읽음 ( sum = 2,000 )
- TX2: ①번 update 실행 ( 7번 계좌 1,100 )
- TX1: 6번 계좌까지 읽음 ( sum = 6,000 )
- TX2: ②번 update 실행 후, 커밋 ( 3번 계좌 900, 7번 계좌 1,100 언커밋 )
- TX1: 모두 읽으면 바뀐 7번 계좌를 읽어 총합은 10,100 이 된다.
위 두 사례의 현상은 오라클 데이터베이스에서는 우려하지 않아도 되는 현상으로 완벽한 문장수준 읽기 일관성을 보장하기 때문이다.
(2) Consistent 모드 블록 읽기
쿼리 시작 시점을 기준으로 데이터를 읽으며 쿼리 시작 전에 이미 커밋된 데이터만 읽고, 쿼리 시작 이후엔 커밋된 변경사항은 읽지 않는다.
Current 블록은 디스크로부터 읽혀진 후 사용자의 갱신사항이 반영된 최종 상태의 원본 블록이다.
CR 블록은 Current 블록에 대한 복사본이다.
Current 블록 : CR 블록 = 1 : N

Consistent 모드는 SCN(Systen Commit Number)이라는 시간 정보를 이용하여 데이터베이스의 일관성 있는 상태를 식별한다.
SCN은 읽기 일관성과 동시성 제어를 위해 사용되고, 생성된 Redo 로그 정보의 순서를 식별하는데 사용되며, 데이터 복구를 위해서도 사용된다.
블록이 마지막으로 변경된 시점 정보를 식별하기 위해 모든 블록 헤더에 SCN(System Change Number) 정보를 관리하는데 이를 블록 SCN 이라 한다.
(3) Consistent 모드 블록 읽기 세부 원리
모든 쿼리는 Global 변수인 SCN(System Commit Number) 값을 먼저 확인하고 나서 읽기 작업을 시작하는 것을 쿼리 SCN 또는 스냅샷 SCN 이라 한다.
쿼리 SCN 으로 Consistent 모드로 읽을 때 어떻게 일관성을 유지하는지 3가지 경우로 살펴보자.
- 「Current 블록 SCN <= 쿼리 SCN」, committed 상태
- Consistent 모드의 데이터 읽기는 해당 상태에서만 가능하다.
- 「Current 블록 SCN > 쿼리 SCN」, committed 상태
- 블록에 변경이 가해지고 커밋되었다는 의미

- 이 상태에선 CR 블록을 복사본하여 먼저 생성(과거로 되돌리기 위함)
- Undo 레코드 읽어 한 단계 되돌렸는데 상태가 여전하면 UBA가 가리키는 Undo 레코드를 찾기 위해 계속 반복
TX1> update emp set sal = sal + 1 where empno = 7900;
위 쿼리를 반복 수행할 때마다 다른 세션에서 아래 쿼리 수행해보자.
TX2> set autotrace on statistics TX2> select * from emp where empno = 7900; Statistics ------------------------------------------ 0 recursive calls 0 db block gets 4 consistent gets -> 이 값 계속 증가 0 physical reads
update 횟수 증가할 때마다 consistent gets도 하나씩 증가한다.
10g 부터는 IMU(In-Memory Undo) 매커니즘으로 Undo 를 참조하지 않고 Shared Pool의 IMU Pool 의 값을 이용하여 증가하지 않는다
alter session set "_in_memory_undo" = false;
위처럼 파라미터 변경할 수 없다면 1,000번 쯤 update 수행하면 IMU Flush가 발생하여 이후 정상적으로 증가한다.
IMU(In-Memory Undo)
10g 부터 추가된 힌트
_in_memory_undo 와 _imu_pools 에 의해 제어된다.
Undo 세그먼트가 아닌 Shared Pool 내의 미리 할당된 IMU Pool(KTI-Undo) 에 생성된다.
In memory undo latch 에 의해 보호된다.
- 「Current 블록이 Active 상태, 즉 갱신 진행 중 표시」
- 일단 트랜잭션 테이블로부터 커밋 정보를 읽어 블록 클린아웃 시도
- 커밋된 블록이면 읽고, 그렇지 않으면 CR Copy 를 만들어 쿼리 SCN보다 낮은 마지막 커밋 상태로 되돌려 읽음
< 상황 1 >
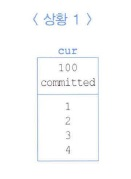
쿼리 SCN 105이 위 블록 Current 블록 SCN 100 을 만나면 커밋 상태이므로 그대로 읽는다.
< 상황 2 >
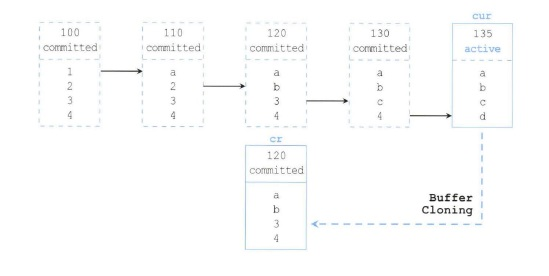
위는 Current 블록이 4번의 갱신을 SCN 이 135로 증가한 상황이다.
쿼리 SCN 125 가 위 블록을 읽을 때 Current 블록이 Active 상태이며 블록 SCN이 더 높아 CR Copy 를 만들고 롤백하여 125 보다 낮은 120 시점에서 읽는다.
< 상황 3 >

상황 2와 같은 상황이지만 이번엔 Current 블록 SCN 보다 큰 쿼리 SCN 이 수행되는 경우다.
쿼리 SCN 145라면 Current 블록 SCN 이 낮지만 active 상태이므로 이 블록을 복사한 후 130 상태로 롤백하고나서 읽는다.
< 상황 4 >
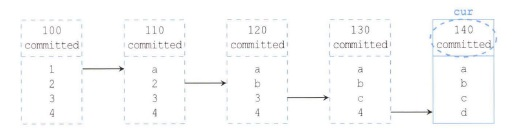
쿼리 SCN 이 150
상황 1과 동일한 상황이다.
< 상황 5 >
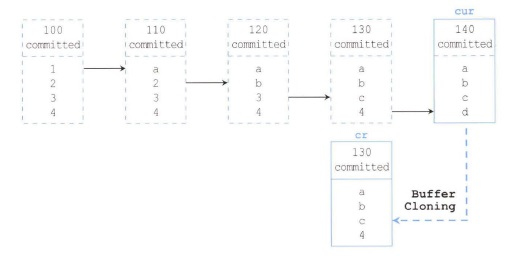
Current 블록이 커밋된 상태이지만 SCN이 140이므로 이 블록을 복사한 후 130 시점으로 롤백한 CR 블록을 읽는다.
DBA 당 CR 개수
버퍼 캐시가 같은 블록에 CR Copy(Cloned Buffer)로 가득차는 일을 방지하기 위해 데이터 블록당 6개 까지만 허용한다.
이를 제어하는 파라미터가 _db_block_max_cr_dba다.
CR Copy 는 항상 LRU end 쪽에 위치하여 Free 버퍼가 필요할 때 1순위로 밀린다.
07 Consistent vs Current 모드 읽기
(1) 차이점
Consistent 모드 읽기(gets in consistent mode)
- SCN 확인 과정 및 쿼리 시작 시점 기준으로 일관성 있는 상태로 블록 액세스
- SQL 트레이스 Call 통계에의 query, AutoTrace 에서의 consistent gets 항목이 Consistent 모드에서 읽은 블록 수
Current 모드 읽기(gets in current mode)
- 데이터를 찾아간 시점의 최종 값의 블록 액세스
- SCN 을 따지지 않고 커밋된 값이면 그대로 받아들임
- SQL 트레이스 Call 통계에의 current, AutoTrace 에서의 db block gets 항목이 Consistent 모드에서 읽은 블록 수
- 다음 상황에 나타남
- DML 수행 및 인덱스 많을수록 더 많이 나타남
- SELECT FOR UPDATE 문도 발견 가능
- 대량의 데이터 정렬 시
(2) Consistent 모드로 갱신할 때 현상
EMP 테이블의 7788번 사원의 SAL 이 1,000 일 때 아래 TX1, TX2 두 개의 트랜잭션이 동시에 수행되면 양쪽 트랜잭션 완료 후 SAL 값은 얼마일까?

Consistent 모드는 쿼리 시작 시점을 기준으로 값을 읽는다.
Dirty Read 를 허용하지 않는 한 두 시점은 1,000 이므로 둘 다 1,000을 읽고 갱신을 완료한다.
그래서 최종 값은 1,200 이며 TX1 의 처리 결과는 사라져 Lost Update가 발생한다.
이는 Current 모드로 Lost Update 를 피할 수 있다.
(3) Current 모드로 갱신할 때 현상

Current 모드로 처리하면 TX1, TX2 트랜잭션 모두 커밋되기를 기다렸다 모두 정상적으로 갱신되면 수행하니 최종 값은 3,000 이다.
항상 Current 모드인 Sybase, SQL Server 같은 DBMS 는 위 결과가 나온다.
한 가지 경우를 더 보자.

위 처럼 TX1이 1 ~ 100,000 까지의 유니크한 번호를 가진 테이블에 no > 50000 조건에 순차적을 갱신 작업을 할 때 100,001 레코드를 새로 추가하면 50,001건이 갱신된다.
인덱스로 no 값을 순차로 읽지 않고 Full Table Scan 으로 Update 를 진행하면 삽입 위치에 따라 결과 건수가 달라진다.
이미 진행된 블록은 제외하고 아직 진행안된 레코드는 갱신 대상에 포함된다.
(4) Consistent 모드로 읽고, Current 모드로 갱신할 때 생기는 현상
오라클에서는 Update 문을 수행하면, 대상 레코드를 읽을 때는 Consistent 모드로 읽고 실제 값을 변경할 때는 Current 모드로 읽는다.
∴ 읽기 위한 블록 액세스는 SQL 트레이스에서 query 항목으로 계산, 변경하기 위한 블록 액세스는 current 항목에 계산

TX2 는 TX1 커밋되길 기다렸다 수행하니 1,100으로 읽어 실패한다.
(5) Consistent 모드로 갱신 대상 실벽하고 Current 모드로 갱신
실제 오라클은 어떻게 두 개의 읽기 모드가 공존할까

단계 1. where 절의 조건으로 대상 레코드 rowid 를 Consistent 모드로 찾음( DML 시작 기준 )
- 대상 건 모두 추출하지 않고 Fetch 하면서 건건이 단계 2 반복 수행
단계 2. rowid가 가리키는 레코드를 찾아가 로우 Lock을 설정 후 Current 모드로 실제 수정/삭제 수행( 완료 시점 )
∴ select 는 Consistent 모드. insert, update, merge는 Current 모드로 읽고 씀 다만, 갱신할 대상 식별하는 작업은 Consistent 모드로 이루어진다.
Write Consistency
앞서 사례에서 Consistent 와 Current 모드가 서로 달라 TX2 update 가 실패했다. 이를 방지하고자 오라클은 Restart 메커니즘을 사용한다.
갱신을 롤백하고 update를 첨부터 다시 실행한다.
Where 절에 사용된 컬럼 값이 바뀌었을 때만 작동한다.
(6) 오라클에서 일관성 없게 갱신하는 사례
독특하게 갱신 오류가 발생하는 사례 중 하나 (함수/프로시저/트리거 등)

첫 문장은 계좌1.잔고는 Consistent 모드, 계좌2.잔고는 Current 모드로 읽는다.
∴ 계좌1에 변경이 발생해도 update 시작 시점으로 찾아 읽는다.
두 번째 문장은 계좌2의 값을 스칼라 내에 참고하여 서브 쿼리도 Current 모드로 작동하게 된다.
∴ 계좌1에 변경 발생하면 조인에 실패해 NULL 값으로 업데이트된다.
08 블록 클린아웃
블록 클린아웃(Block Cleanout)은 트랜잭션에 의해 설정된 로우 Lock을 해제하고 블록 헤더에 커밋 정보를 기록하는 오퍼레이션
대량의 갱신작업은 해당 블록을 일일이 찾으면 오래 걸리니 커밋 정보를 트랜잭션 테이블에만 기록하고 빠르게 커밋한다.
그럼 블록 클린 아웃하는 시점은 언제일까?
나중에 해당 블록이 처음 액세스되는 시점이고 항상 이 방식은 아니며, 오라클은 Delayed 블록 클린아웃과 커밋 클린 아웃 두 메커니즘을 사용한다.
(1) Delayed 블록 클린아웃
트랜잭션이 갱신한 블록 개수가 총 버퍼 캐시 블록 개수의 1/10을 초과할 때 사용하는 방식이며 커밋 후 해당 블록을 액세스하는 첫 번째 쿼리에 의해 클린아웃이 이루어진다.
아래의 작업을 수행한다.
- ITL 슬롯에 커밋 정보 저장
- 레코드에 기록된 Lock Byte 해제
- Online Redo 에 Logging 및 블록 SCN 변경
(2) 커밋 클린아웃(Fast 블록 클린아웃)
트랜잭션이 갱신한 블록 개수가 총 버퍼 캐시 블록 개수의 1/10을 이하일 때 사용하는 방식
아래의 작업을 수행한다.
- ITL 슬롯에 커밋 정보 저장
- Lock Byte를 무시 즉, 해제하지 않음
- Online Redo 에 Logging 을 남기지 않음 (로깅 시점을 미룸)
- 블록 갱신을 위해 Current 모드로 읽는 시점(ITL 슬롯 필요)에 Lock Byte를 해제하고 Online Redo 에 로깅
(3) ITL 과 블록 클린 아웃

|
슬롯
|
설명
|
|
1번
|
Lock Byte 가 해제되지 않은 상태(Lck = 1)에 SCN이 fsc, Flag는 U가 표시되어 Fast 클린 아웃
|
|
2번
|
Flag가 C이며 Lock Byte가 해제되어 Delayed 블록 클린아웃에 의해 클린아웃된 경우
|
|
3번
|
Flag가 C-U-이며 Lock Byte가 해제되어 추정된 커밋 SCN(다음 절)인 경우
|
09 Snapshot too old
이 발생원인은 두 가지로 요약할 수 있다.
- 데이터를 읽다 쿼리 SNC 이 변경된 블록을 만나 롤백할 때, Undo 블록이 다른 트랜잭션에 의해 이미 재사용돼 Undo 정보를 못얻는 경우
- 커밋된 트랜잭션 테이블 슬롯이 다른 트랜잭션에 의해 재사용돼 커밋 정보를 확인할 수 없는 경우
위의 두 경우는 Undo 세그먼트가 너무 작은 신호일 수 있다.
(1) Undo 실패

- SCN 123 시점에 쿼리 시작
- 쿼리 진행 중 다른 트랜잭션에서 데이터를 변경, 이때 SCN 은 129
- 해당 변경내역을 담은 Undo 블록이 다른 트랜잭션에 의해 재사용
- 변경사항의 블록에 도달하여 자신의 쿼리 123보다 큰 129임을 확인하고 Undo 블록을 찾아감
- 하지만 다른 트랜잭션에 의해 재사용된 상태여서 에러를 발생
for C in (select /*+ ordered use nl(b) */ A.고객ID,A.입금액,B.수납액 from 은행입금 A, 수납 B where A.입금일자 = trunc(sysdate) and B.수납년월(+) = to char(sysdate, 'yyyymm') and B.고객ID(+) = A.고객ID) loop if C.수납액 IS NULL then insert into 수납(고객ID,수납년월, 수납액) values ( C.고객ID, to char(sysdate, 'yyyymm'), C.입금액) else update 수납 set 수납액 = 수납액 + C.입금액 where 고객ID = C.고객ID and 수납년월 = to_char(sysdate, 'yyyymm') end if; commit; end loop;
위와 같은 코딩 패턴을 fetch across commit 이라고 한다.
명시적으로 로우 하나씩 Fetch 하며 값을 변경하며 계속 커밋을 날리는 방식이다.
(2) 블록 클린아웃 실패
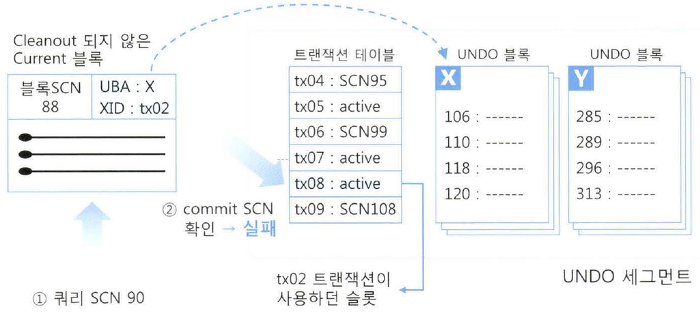
변경된 블록을 모두 클린아웃하지 않은 상태에서 Free 상태로 변경하면 다른 트랜잭션에 의해 재사용될 수 있다.
시간이 흘러 변경된 블록이 읽혀야 할 시점에 Delayed 블록 클린아웃을 위해 슬롯을 찾아갔는데 다른 트랜잭션에 의해 이미 재사용됐다면 일관성 모드 읽기가 불가능해질 수 있다.
트랜잭션 슬롯이 필요해지면 커밋 SCN이 가장 낮은 트랜잭션 슬롯부터 재사용하는데, 해당 커밋 SCN을 Undo 세그먼트 헤더에 최저 커밋 SCN으로 기록해 둔다.
최저 커밋 SCN이 쿼리 SCN 보다 높아질 정도로 트랜잭션이 몰려 에러를 발생시킬 수 있다.
(3) Snapshot too old 회피 방법
- 불필요하게 커밋을 자주 수행하지 않음
- fetch across commit 형태 코딩
- 트랜잭션 몰리는 시간대에 오래 걸리는 쿼리가 수행안되게 시간 조정
- 큰 테이블을 일정 범위로 나누어 단계적으로 실행할 수 있게 코딩
- 특정 부분부터 다시 시작되도록 유도
- Nested Loop 조인 또는 인덱스 경유를 회피(조인 메소드 변경, Full Table Scan)
- Order by 등의 소트 연산 발생토록함.
- 소트로 같은 블록을 재방문해도 에러가 발생하지 않도록 유도
- Delayed 블록 클린아웃에 의해 Snapshot too old 의심되면 Full Scan 하도록 쿼리 날림
- select /*+ full(t) */ count(*) from table_name t
- 인덱스 블록 문제로 판단시 인덱스 리프 블록 모두 스캔하도록 쿼리
- select count(*) from table_name where index_column > 0
10 대기 이벤트
(1) 대기 이벤트란
오라클 프로세스는 일을 계속 진행할 수 있는 충족이 될 때까지 수면(sleep) 상태에 빠지는데, 이 현상을 대기 이벤트(wait event)라고 한다.
수면에 빠지는 것은 프로세스가 wait queue로 옮겨져 CPU를 할당해줄 필요가 없어 스케쥴링 대상에서 제외된 상태를 말한다.
(2) 대기 이벤트 발생 시점
|
발생 시점
|
관련 이벤트
|
|
자신이 필요한 리소스가 다른 프로세스에 의해 사용중
|
buffer busy waits, latch free, enqueue 이벤트 등
|
|
다른 프로세스에 의해 선행작업 완료되길 기다릴 때
|
write complete waits, checkpoint completed, log file sync, log file switch 이벤트 등
|
|
할 일 없을 때 ( idle 대기 이벤트 )
|
SQL*Net messsage from client, PX Deq:Execution Msg 등
|
(3) 대기 이벤트는 사라지는 시점
대기 중이던 프로세스가 활동을 재개하는 시점은 다음과 같다.
- 대기 상태에 빠진 프로세스가 기다리던 리소스가 사용 가능해짐
- 작업을 계속 진행하기 위한 선행작업 완료
- 해야 할 일이 생겼을 때
(4) 래치와 대기 이벤트 개념 명확화
대기 이벤트와 래치가 구분이 안될 수 있어 구별되어야한다.
v$latch 뷰를 조회하면 각 래치 항목이 있는데 여기선 willing-to-wait 모드 래치 요청만 설명하고 immediate 모드 래치 요청을 포함한 래치에 대한 깊은 학습을 원하면 OWI(Oracle Wait Interface)를 따로 공부하자.
|
항목
|
설명
|
|
gets
|
래치 요청 횟수
|
|
misses
|
다른 프로세스가 사용 중이어서 래치 요청해도 첫 번째 시도에서 얻지 못한 횟수
gets 에서 misses 횟수를 빼면 래치 해제를 안기다리고 곧바로 획득에 성공한 횟수이다
simple_gets = gets - misses
|
|
spin_gets
|
첫 번째 시도에 래치 획득 실패했지만 이후 spin 과정에 래치 획득 성공한 횟수
misses 에서 sleeps 를 뺀 횟수와 일치
즉, 첫 시도에 얻지 못해도 Sleep 전에 얻는 경우이다.
|
|
sleeps
|
요청했는데 못 얻고 정해진 횟수만큼 계속 시도해도 못 얻어 대기상태로 빠진 횟수
이때 발생하는 것이 latch free 대기 이벤트
우선권이 없으면 가장 먼저 요구해도 늦게 얻을 수 있다.
|
11 Shared Pool
Shared Pool은 SGA 중 가장 중요한 구성요소 중 하나 (추후에 더 자세히 설명)
크게 딕셔너리 캐시(Dictionary Cache)와 라이브러리 캐시(Library Cache)로 나뉨
(1) 딕셔너리 캐시
테이블, 인덱스, 테이블 스페이스, 데이터파일, 세그먼트, 익스텐트, 사용자, 제약, 시퀀스, DB Link 등의 정보들을 캐시영역에 캐싱하여 입출력을 빠르게 한다.
Row 단위로 읽고 쓰기 때문에 로우 캐시(Row Cache) 라고도 한다.
Sequence Cache 옵션
잦은 채번은 로우 캐시에 경합을 발생시키게 된다. 이를 해소하기 위한 옵션이다.
Cache 크기가 10이면 Nocache 보다 로우 캐시를 갱신하는 횟수가 1/10 준다.
동시에 채번이 많이 발생하는 시퀀스 일수록 cache 사이즈를 크게 설정하는 것도 중요한 튜닝 중 하나다.
기본 설정값은 20이다.
딕셔너리 캐시 활동성은 v$rowcache 에 확인할 수 있으며 히트율(Hit Ratio) 수치가 낮으면 Shared Pool 사이즈를 늘리는 고려를 해야한다.

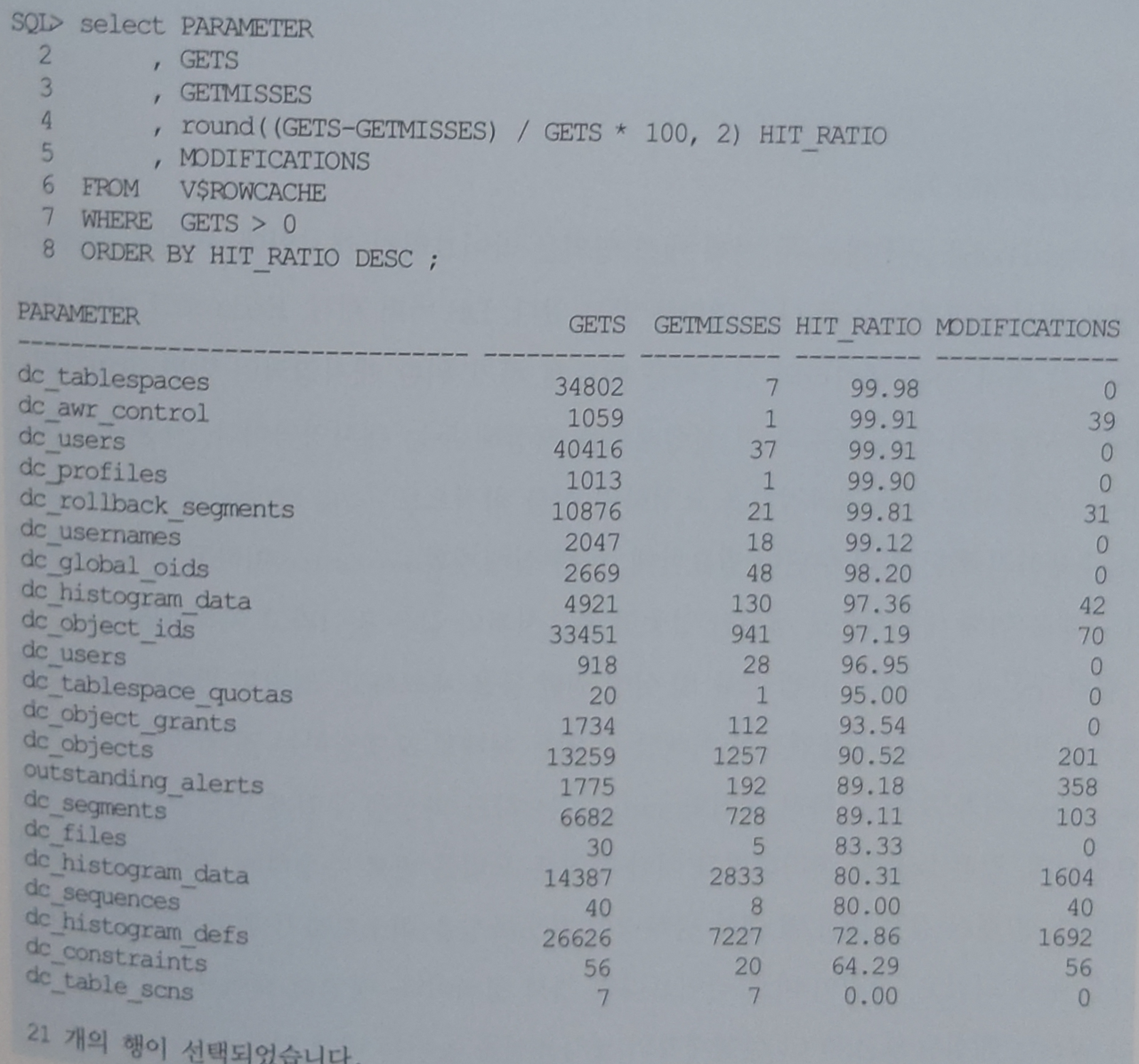
v$rowcache 에서 TYPE = 'PARENT' 와 v$latch_children 에서 'row cache objects' 의 래치 개수를 조회하면 항상 값이 일치하는 것을 볼 수 있다.
이는 로우 캐시에 관리하는 엔트리 각각에 하나의 래치가 할당된 것을 짐작할 수 있다.

(2) 라이브러리 캐시
사용자가 던진 SQL과 그 실행계획을 저장해 두는 캐시영역이다.
SQL 명령어로 결과집합을 요청하면 이를 최적으로(적은 리소스로 가장 빠르게) 수행하기 위한 처리 루틴을 실행계획(execution plan)이라 한다.
쿼리를 분석해 문법 오류 및 실행 권한을 체크하고, 최적화 과정을 거쳐 실행 계획을 만들어 이해 가능한 형태로 포맷팅하는 과정을 하드 파싱(Hard Parsing)이라 한다.
최적화를 위해 하드 파싱을 무겁게 만드는데 이 작업을 반복하면 비효율
∴ 라이브러리 캐시 영역으로 재사용성을 높임
'Oracle' 카테고리의 다른 글
| [오라클] 전화번호 포맷 변경 쿼리 (하이픈, 자르기) (0) | 2023.03.02 |
|---|---|
| Oracle 대량 데이터 삽입 insert 빠르게 실행 벌크 insert : FORALL (0) | 2023.03.02 |
| 하위 Client에서 Oracle 19c 접속 (0) | 2023.03.02 |
| oracle error 코드 및 해결방법 (0) | 2023.03.02 |
| 오라클DB 점검사항 (0) | 2023.03.02 |